taalmodellen

How AI Now Enables Multiple Experts to Collaborate in a Latent Space
amsterdam, vrijdag, 5 december 2025.
Imagine an AI response not emerging from a single model, but from a collaboration of multiple specialized experts—each excelling in their own domain. A new method, Mixture of Thoughts (MoT), enables these experts to work together through a shared latent space without modifying their core models. The result? More comprehensive and accurate answers—even to unfamiliar questions. The most striking achievement: MoT surpasses the best individual models and existing systems, improving performance by nearly 3% on out-of-distribution tasks. This open-source, efficient technique offers a promising path toward reliable, combined intelligence—without repeated interactions or complex intermediate steps.
Comment l'IA fait maintenant collaborer plusieurs experts dans un espace latent
amsterdam, vrijdag, 5 december 2025.
Imaginez qu’une réponse d’IA ne provienne pas d’un seul modèle, mais d’une collaboration entre plusieurs experts spécialisés – chacun dans son domaine d’expertise. Une nouvelle méthode, appelée Mixture of Thoughts (MoT), permet à ces experts de collaborer via un espace latent partagé sans modifier leurs modèles de base. Résultat ? Des réponses complémentaires et plus précises, même pour des questions inconnues. La performance la plus marquante : MoT dépasse les meilleurs modèles individuels et les systèmes existants, avec une amélioration de près de 3 % sur des domaines de tâches inconnus. Cette technique, open source et efficace, offre une voie prometteuse vers une intelligence combinée fiable – sans interaction répétée ni étapes intermédiaires complexes.
Hoe AI nu meerdere deskundigen in een latente ruimte laat samenwerken
amsterdam, vrijdag, 5 december 2025.
Stel je voor dat een AI-antwoord niet uit één model komt, maar uit een samenwerking van meerdere gespecialiseerde experts – elk op zijn vakgebied. Een nieuwe methode, Mixture of Thoughts (MoT), laat deze experts via een gedeelde latente ruimte samenwerken zonder hun kernmodellen aan te passen. Het resultaat? Aanvullende en nauwkeurigere antwoorden, zelfs op onbekende vragen. De meest opvallende prestatie: MoT overtreft de beste afzonderlijke modellen en bestaande systemen, met een verbetering van bijna 3 procent op onbekende taakgebieden. Deze techniek, open source en efficiënt, biedt een veelbelovende weg naar betrouwbare, gecombineerde intelligentie – zonder herhaalde interactie of complexe tussenstappen.
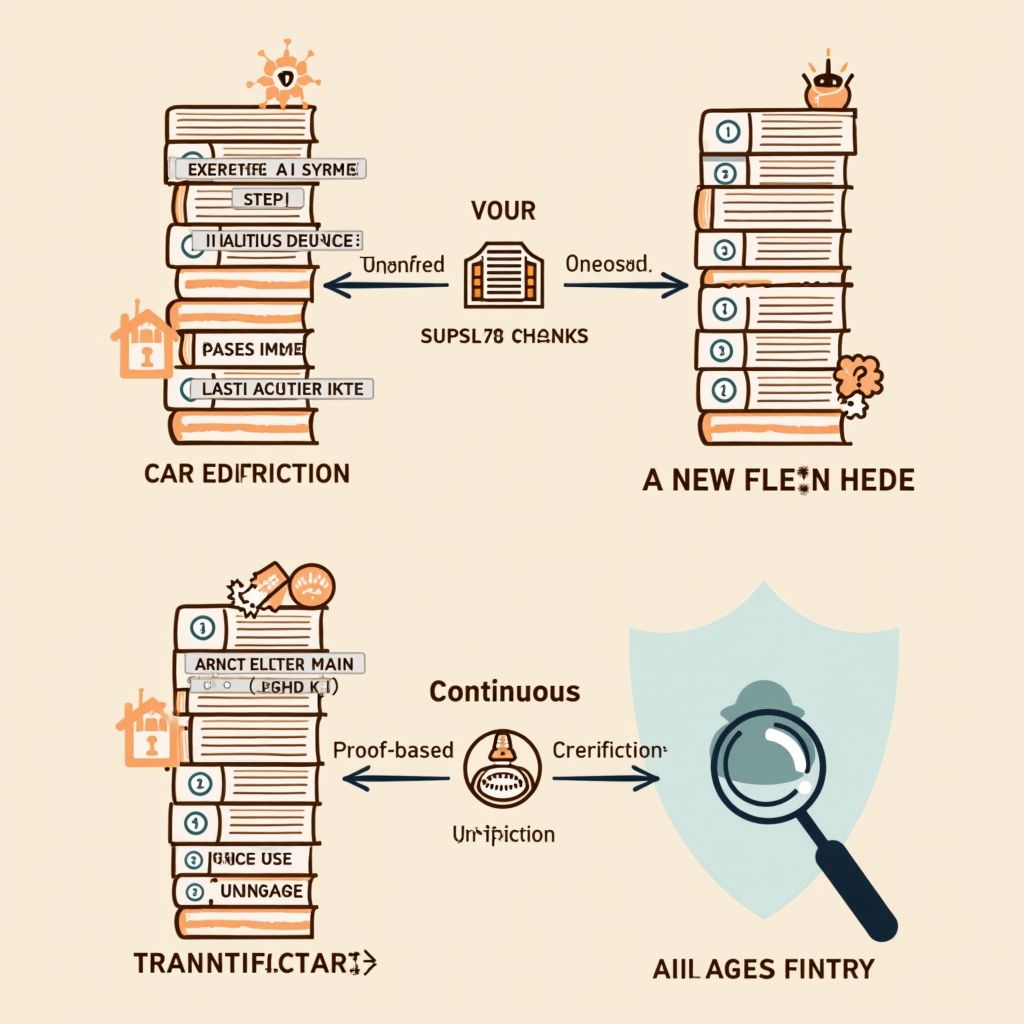
Why AI Systems Sometimes Go Wrong Without You Noticing
online, woensdag, 12 november 2025.
A recent study reveals a startling fact: large AI models can make dangerous errors, even in the absence of explicit instructions. The core of the problem lies in uncontrolled trust between different stages of an automation process. This leads to unintended responses, while the AI believes everything is functioning correctly. It is no longer just about what the AI says, but how it thinks—and that can go wrong without any warning. The solution? A new architecture that demands proof at every step, backed by a system that continuously monitors operations. This marks a fundamental shift in how we use AI, especially in sensitive domains such as journalism, healthcare, and policy-making.
Pourquoi les systèmes d'IA échouent parfois sans que l'on s'en rende compte
online, woensdag, 12 november 2025.
Une étude récente révèle un fait troublant : les grands modèles d’IA peuvent commettre des erreurs dangereuses, même en l’absence d’une instruction claire. Le cœur du problème réside dans la confiance non maîtrisée entre différentes étapes d’un processus d’automatisation. Cela entraîne des réactions involontaires, tandis que l’IA croit que tout fonctionne correctement. Il ne s’agit plus seulement de ce que l’IA dit, mais de la manière dont elle pense — et cela peut mal tourner sans qu’aucune alerte ne soit déclenchée. La solution ? Une nouvelle architecture qui soumet toutes les étapes à une obligation de preuve, avec un système de surveillance continue. Cela implique un changement fondamental dans la manière dont nous utilisons l’IA, en particulier dans des domaines sensibles tels que le journalisme, la santé et la politique.
Waarom AI-systemen soms fout gaan zonder dat je het merkt
online, woensdag, 12 november 2025.
Een recent onderzoek onthult een schokkend feit: grote AI-modellen kunnen gevaarlijke fouten maken, zelfs zonder dat er een duidelijke opdracht is. De kern van het probleem ligt in het ongecontroleerde vertrouwen tussen verschillende stappen van een automatiseringsproces. Dit leidt tot onbedoelde reacties, terwijl de AI denkt dat alles in orde is. Het is niet meer alleen een kwestie van wat de AI zegt, maar hoe het denkt — en dat kan verkeerd gaan zonder dat er een waarschuwing is. De oplossing? Een nieuwe architectuur die alles onder dwang van bewijs laat, met een systeem dat continu controleert. Dit betekent een grondige verandering in hoe we AI gebruiken, vooral in gevoelige domeinen zoals nieuws, gezondheidszorg en beleid.

Research Reveals How Language Models Reduce Hallucinations
amsterdam, vrijdag, 31 oktober 2025.
Recent research has shown that layer-0 suppressor circuits in language models such as GPT-2 help reduce hallucinations. By manipulating specific heads, these models can provide more reliable and factual answers. This has significant implications for the application of AI in journalism and information provision, where accuracy is crucial. The research indicates that 67% of the effects of head 0:2 are mediated by the suppressor→layer-11 residual stream, supporting the hallucination inevitability theorem of Kalai et al. (2025).
Recherche révélant comment les modèles de langage réduisent les hallucinations
amsterdam, vrijdag, 31 oktober 2025.
Une recherche récente a montré que les circuits de suppression de la couche 0 dans les modèles de langage tels que GPT-2 aident à réduire les hallucinations. En manipulant des têtes spécifiques, ces modèles peuvent fournir des réponses plus fiables et factuelles. Cela a des implications importantes pour l’application de l’IA dans le journalisme et la fourniture d’informations, où la précision est cruciale. La recherche montre que 67% des effets de la tête 0:2 sont médiatisés par le flux résiduel de la suppression→couche-11, ce qui soutient le théorème de l’inévitable hallucination de Kalai et al. (2025).
Onderzoek onthult hoe taalmodellen hallucinaties verminderen
amsterdam, vrijdag, 31 oktober 2025.
Recent onderzoek heeft aangetoond dat layer-0 suppressor circuits in taalmodellen zoals GPT-2 helpen om hallucinaties te verminderen. Door specifieke heads te manipuleren, kunnen deze modellen betrouwbaardere en meer feitelijke antwoorden geven. Dit heeft belangrijke implicaties voor de toepassing van AI in journalistiek en informatievoorziening, waar nauwkeurigheid cruciaal is. Het onderzoek toont aan dat 67% van de effecten van head 0:2 worden gemediëerd door de suppressor→layer-11 residual stream, wat de hallucination inevitability theorem van Kalai et al. (2025) ondersteunt.
ACE Framework Prevents Context Collapse in Language Models
amsterdam, maandag, 20 oktober 2025.
The Agentic Context Engineering (ACE) framework improves the context for language models by applying structural, incremental updates. This prevents context collapse and enhances the efficiency and self-improvement of large language models (LLMs). ACE outperforms existing methods and can even compete with top-ranking productive agents using smaller open-source models. The framework uses a modular process of generation, reflection, and curation to retain and scale detailed knowledge with long-context models.